MapReduce Explained!

Hi I'm Shivam Ahirao. I'm a quick learner working as a Software Engineer.
This article is a part of Big-Data series in which I'll be posting stuff related to Big data tech stack. Most of the articles will be short and to the point.
If you're following along in the Big-Data series where we talked about Hadoop and one of the most crucial part of Hadoop aka The heart of Hadoop in the previous blog post - HDFS Explained. Now it's time to decipher the brain of Hadoop .i.e.. MapReduce.
MapReduce
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster. A MapReduce program is composed of a map procedure, which performs filtering and sorting, and a reduce method, which performs a summary operation.
( Wikipedia )
They say:

But let's try to understand it the easy way!
- MapReduce is the computing layer of Hadoop.
- It is responsible for processing large amount of data parallelly/ distributedly.
- The computation is done parallelly on the physical servers .i.e. commodity hardware.
- The MapReduce is designed to work on large set of data.
Since the Hadoop stores data distributedly via HDFS so it allows MapReduce to do the processing parallelly over the cluster.
How MapReduce works?
- It divides the work into independent tasks, lots of nodes work in parallel this way high processing power is achieved.
- MapReduce works on the concept of Data locality:
Data Locality: Instead of moving data close to the code, Code (computation) should be moved close to the data.
MR job and Task
MR Job
- Client is responsible to create/code a MR(Map Reduce) job.
- Client creates the job, configures it and submits it to Master.
- Master sends copy of this MR job(code) to each node .i.e. slaves.
MapReduce supports various languages : C, C++, Java, Ruby, Python etc.

Task
- An execution of a mapper and Reducer on a slice of data.
- Master divides the work into tasks and schedules it on the slave.
MapReduce Daemons:

Mapper and Reducer

Mapper :
- A program that performs Map phase using Map() function in MapReduce job.
- Takes data in the form of Key value pairs.
- Ideally 10-100 maps/node.
Reducer :
- A program that performs Reduce phase using Reduce() function in MapReduce job.
- Takes data in the form of Key value pairs from mapper.
- Accepts o/p of mapper as the input.
MapReduce data elements are always structured as key value(K,V) pairs.
Phases of MapReduce
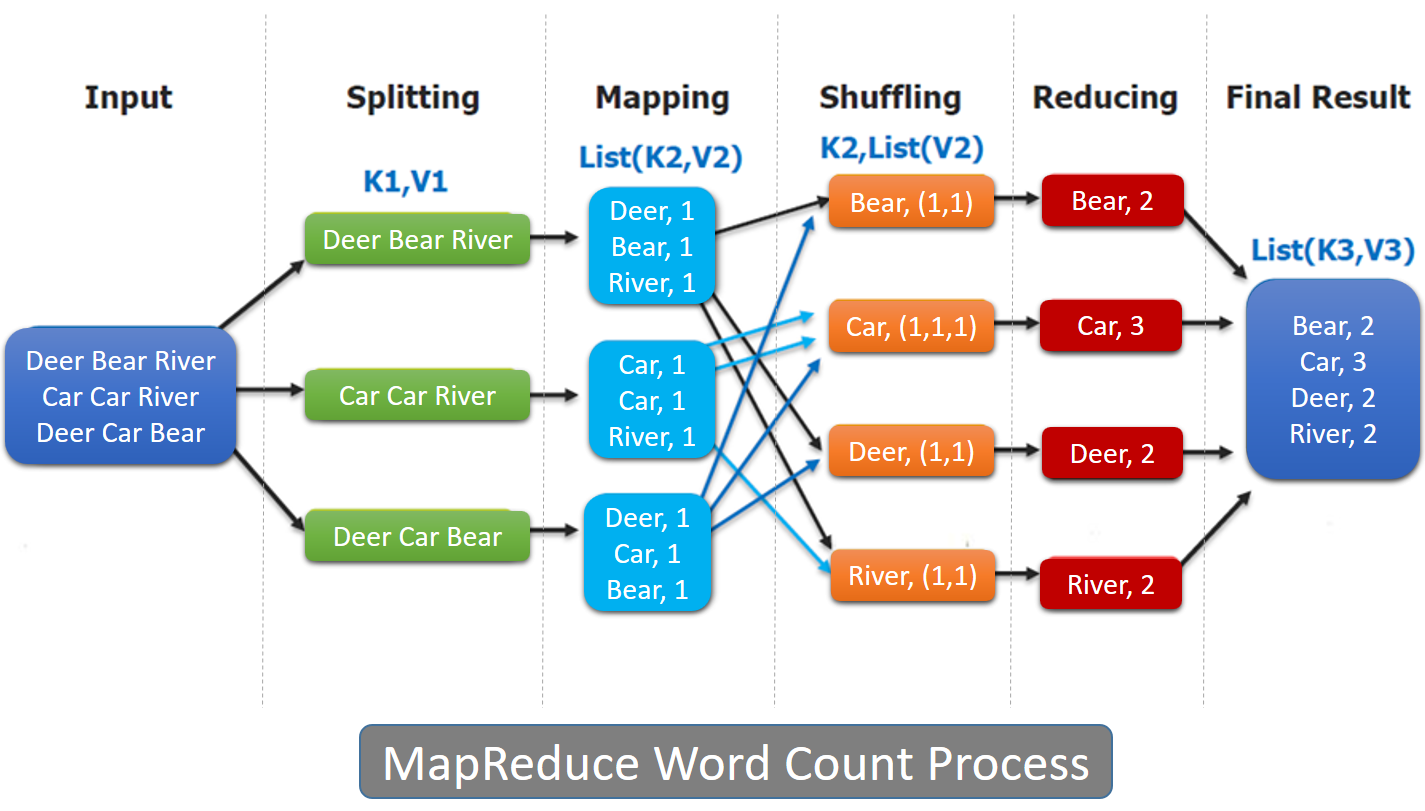
Let's understand the concept covered in image in 3 steps:
- Map stage divides the input data into key value pairs.
- Shuffle/Sort is a stage which makes sure that all the data is stored in same node.
- Reduce stage returns single value for each key.
Well this is enough for one go!
So now finally you can say!!




