HDFS Explained!

Hi I'm Shivam Ahirao. I'm a quick learner working as a Software Engineer.
This article is a part of Big-Data series in which I'll be posting stuff related to Big data tech stack. Most of the articles will be short and to the point.
As said in previous Blog post HDFS is the heart of Hadoop. That being said it is responsible for the Distributed Data Storage and Data Protection.
HDFS: Hadoop Distributed File System
Like any other distributed file system Hadoop works in master-slave fashion. But the major difference between Hadoop Distributed file system i.e HDFS and others is it's fault tolerant behavior. At any point of time HDFS maintains atleast 3 copies of data on various data nodes(slaves).
Characteristic of HDFS:
- HDFS is the storage layer in the Hadoop ecosystem.
- It is one of the most reliable storage layer.
- It is distributed file system which runs on commodity hardware.
- It is Highly fault tolerant, Reliable, scalable.
- Works in master - slave fashion.
- By default 3 replicas are made of each block on the slaves.
- Master stores the metadata about the slaves.
- Slave stores the actual data.
There are 2 daemons in HDFS:
1. Master : Namenode
- Regulates access to files by client.
- Manages all slavenodes (datanodes).
- Assigns work to slave nodes.
- Should be deployed on a reliable hardware.
2. Slave : Datanode
- HDFS cluster consists of number of slave nodes.
- Actual data is stored on the Datanode.
- Responsible for performing the operation like read, write from receiving request from client.
- Can be deployed on commodity hardware.
What if Namenode fails ?
- Secondary Namenode comes in action.
What if Datanode fails ?
- Namenode identifies if any datanode fails, and namenode automatically assign other datanode without hampering the process.
What is the default block size in HDFS ?
- HDFS's default block size is of 64 MB.
What is the default replication factor in HDFS and how to change it ?
- Default replication factor in HDFS is 3, we can change it in through in hdfs-site.xml file.
Read File Operation in HDFS:
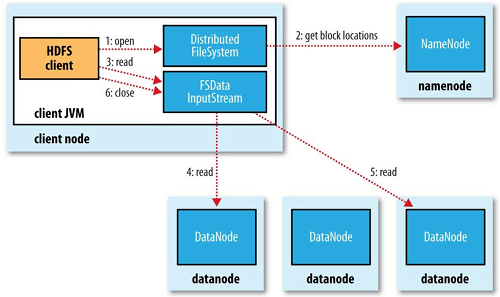
- To read a file HDFS client node interacts with the Namenode.
- The namenode checks for the access rights of the client.
- If the authorization is successful Namenode allows the client to read the file. It send the client the location of the Datanodes (slaves) and blocks.
- After this client goes directly to the Datanodes to read the file.
- Reading is done in parallel.
- Reading is done using : FSData Inputstream
Write File Operation in HDFS:
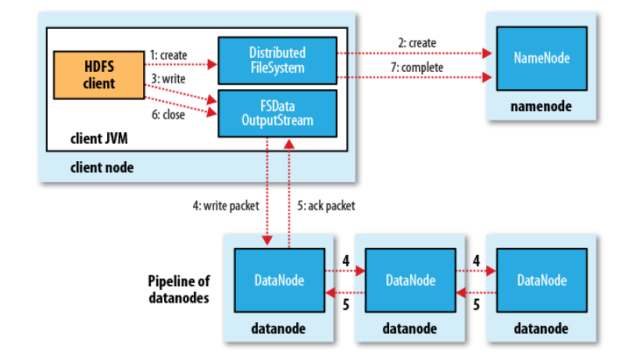
- To write the file HDFS client interacts with the Namenode.
- The Namenode checks for the access right of the HDFS client to write in specific paths.
- If the authorization is granted the Namenode provides the HDFS client the location to write the block.
- Client directly goes to the Datanode (slave) eg. Datanode 1 and start writing the packets parallelly.
- As soon as the block is written the Datanode starts copying/replicating the blocks into another Datanode Eg. Datanode 3.
- Now as soon as the block is written in Datanode 3, this node starts copying the blocks into another eg. Datanode 7.
- As soon as the required level of replication is achieved the Datanode starts sending the acknowledgement :
Datanode 7 -> Datanode 3 -> Datanode 1 -> Final acknowledgment to client
- Writing is done using : FSData Writestream.
Slave is the one which does the replication of data.
The Datanodes ie. slaves are in constant communication with the Namenode.
Reading and writing both are done in parallel.
In next blog post we'll decipher the heart of Hadoop ie. Map-Reduce.
Until next time ;) !



