
Apache Spark: Movie-lens Dataset end to end Data pipeline using Microsoft Azure and Databricks


A movie recommendation system is used by top streaming services like Netflix, Amazon Prime, Hulu, Hotstar, etc to recommend movies to their users based on historical viewing patterns.
Before the final recommendation is made, there is a complex data pipeline that brings data from many sources to the recommendation engine. In this project, I have used Databricks Spark on Azure with Spark SQL to build this data pipeline.
The dataset is from GroupLens Research, which is a research group in the Department of Computer Science and Engineering at the University of Minnesota. They operate a movie recommender based on collaborative filtering called MovieLens.
This dataset (ml-latest) describes 5-star rating and free-text tagging activity from MovieLens, a movie recommendation service. It contains 22884377 ratings and 586994 tag applications across 34208 movies. These data were created by 247753 users between January 09, 1995, and January 29, 2016. This dataset was generated on January 29, 2016.
Here in this article, I have tried to give an overview of how the entire end-to-end pipeline looks like. I have attached the final results of the computation part of the pipeline, the computation (processing) is done on Azure Databricks.
Tech Stack Used:
- Storage: Azure Datalake Storage
- ETL/Data pipeline: Azure Datafactory
- Computation: Azure Databricks/ Databricks community Edition
Steps Involved:
- Building storage account on Azure.
- Uploading Raw data in the Azure Data lake storage.
- Creating an Azure Data factory instance.
- Creating a data pipeline using Azure Datafactory. (To copy data from 1 location to other)
- Creating Azure Databricks instance (Databricks community edition can also be used).
- Creating a databricks cluster.
- Creating a python notebook and accessing the data either from DBFS/Azure data lakes storage etc.
- Performing the computation and EDA on the dataset and plotting it.
You can also view the code directly on Databricks using the below link:
databricks-prod-cloudfront.cloud.databricks..
Results (Dashboard/Charts):
1- Genre distribution ie. Which genre has the highest number of more than 4 rating across entire Dataset
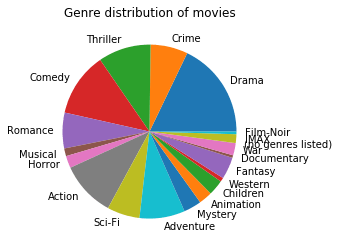
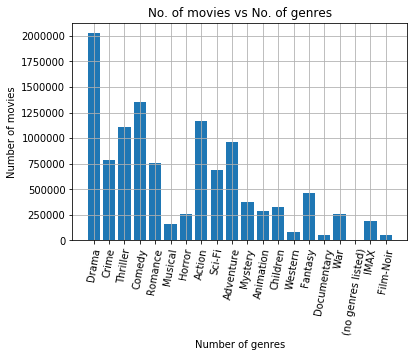
2- Number of movies for each genre
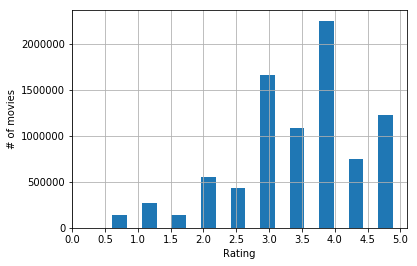
3- Number of ratings (2,3,4,5 etc.)
Github link for the code: github.com/beingshivam/spark_movielens_data..
#apachespark #azure #bigdata #databricks #dataanalysis #datapipeline #dataengineering